聚类是一种无监督学习,将相似的对象归到同一个簇中,类似全自动分类,即类别体系也是自动构建的。聚类方法几乎可以应用于所有对性,簇内的对象越相似,聚类效果越好。K-均值聚类算法可以发现k个不同的簇,且每个簇的中心采用簇中所含值的均值构成。聚类与分类的区别在于,分类的目标事先已知,而聚类未知。
K-均值聚类
- K-均值聚类算法的优点在于容易实现,缺点在于可能收敛到局部最小值,并且在大规模数据上收集较慢。适用于数值型数据。
- K-均值聚类算法发现给定数据集的k个簇,这里的k是用户指定的,其的工作流程如下:首先随机确定k个初始点作为质心(注意这里的k个初始点不一定是数据集中的点,但一定在数据集的range内),然后对数据集中的每个点,寻找距离这个点最近的质心,并将其分配给这个质心对应的簇,该步完成后将每个簇的质心修改为该簇所有点的平均值。伪代码表示如下:
- 创建k个点作为起始质心(通常随机选择)
- 当任意一个点的簇分配结果发生改变时:
- 对数据集中的每个点:
- 对每个质心:
- 计算质心与数据点之间的距离
- 将数据点分配到距离其最近的簇
- 对每一个簇,计算簇中所有点的均值并将均值作为质心。
- K-均值算法要寻找最近的质心,因此需要进行某种距离计算,数据集上K-均值算法的性能会受到所选距离计算方法的影响。函数rendCent用于对数据集dataSet随机初始化k个簇质心,随机质心的大小在测试数据集的最小值和最大值之间。distEclud用于计算两个点之间的欧式距离,也可以切换成其他距离函数。
1 | from numpy import * |
- 函数kMeans接受四个输入参数,用户需要指定数据集和划分的簇数k。kMeans函数一开始确定数据中数据点总数,clusterAssment记录簇分配结果,第一列记录簇索引值,第二列存储误差(当前点到簇的质心的距离)。按照计算质心->分配->重新计算的过程反复迭代,直到所有数据点的簇分配结果不再改变为止。选项axis=0表示沿着矩阵的列方向计算均值。
1 | def kMeans(dataSet, k, distMeas = distEclud, createCent = randCent): |
二分K-均值算法
- 后处理:在K-均值聚类中簇的数目k是用户定义参数,可以利用clusterAssment中的误差值评价聚类分簇的正确性和质量。考虑下图的聚类结果,K-均值聚类算法收敛但聚类效果较差的原因是K-均值算法收敛到了局部最小值,而非全局最小值。可以使用SSE(误差平方和,clusterAssment[:,1]的和)评价聚类好坏,SSE值越小表示数据点越接近于它们的质心,聚类效果也越好。因为对误差取平方,因此更加重视远离质心的点。增加簇的个数必然降低SSE的值,但不符合聚类目标。一种方法是对聚类生成的簇进行后处理,将具有最大SSE值得簇划分为两个簇,具体实现只要将属于最大簇的数据点用K-均值聚类,设定簇数k=2即可。为了保证簇总数不变,可以合并最近的质心,或者合并两个使得SSE值增幅最小的质心。
- 二分K-均值类似后处理的切分思想,初始状态所有数据点属于一个大簇,之后每次选择一个簇切分成两个簇,这个切分满足使SSE值最大程度降低,直到簇数目达到k。另一种思路是每次选择SSE值最大的一个簇进行切分。前者伪代码如下。
- 将所有点看成一个簇
- 当簇数目小于k时
- 对于每一个簇:
- 计算总误差
- 在给定的簇上面进行K-均值聚类(k=2)
- 计算将该簇一分为二后的总误差
- 选择使得误差最小的那个簇进行划分操作
- 函数biKmeans是上面二分K-均值聚类算法的实现,首先创建clusterAssment储存数据集中每个点的分类结果和平方误差,用centList保存所有已经划分的簇,初始状态为整个数据集。while循环不停对簇进行划分,寻找使得SSE值最大程度减小的簇并更新,添加新的簇到centList中。
1 | def biKmeans(dataSet, k, distMeas=distEclud): |
- 运行上述函数多次,聚类会收敛到全局最小值,而kMeans函数偶尔会陷入局部最小值。
1 | >>> datMat3 = mat(kMeans.loadDataSet('testSet2.txt')) |
对地图上的点进行聚类
- 使用Yahho!PlaceFinder API收集数据,筛选出目标地点的经纬度,用matplotlib构建一个二位数据图,包含簇、位置和地图。将俄勒冈州的70个地点聚类,地址列表为portlandClubs,txt。可以在Yahoo开发者网络进行注册,创建一个桌面应用以获取appid。书上给出的yahooAPI的baseurl已经改变,并且yahoo目前的placefinder需要OAuth2验证,要使用该api,须在header里或者get方法中加入六个必须的参数。github上有oauth2供python使用,但是yahoo的BOOS GEO好像OAuth2验证出了问题,虽然写了新的placeFinder调用api的代码,仍然会有403错误,yahoo单方面的问题。几个链接,要vpn:yahoo BOSS GEO的OAuth说明,yahoo placeFinder指南。上面的代码来自书上,下面的是适用于新的api的代码,但会返回403。
1 | import urllib |
- github附书代码里有生成好的place.txt,直接拿来使用。下面代码中,distSLC用球面余弦定理计算地球表面两个点之间的距离,clusterClubs将文件中的地点进行聚类并画出结果。为了画出这些簇,首先创建一幅图和一个矩形,然后用该矩形决定绘制图的哪一部分。
1 | def distSLC(vecA, vecB): |
- 运行结果如下,分别是划分为5个簇、7个簇的情况。多次运行可以找到最佳的分簇数目和方法。
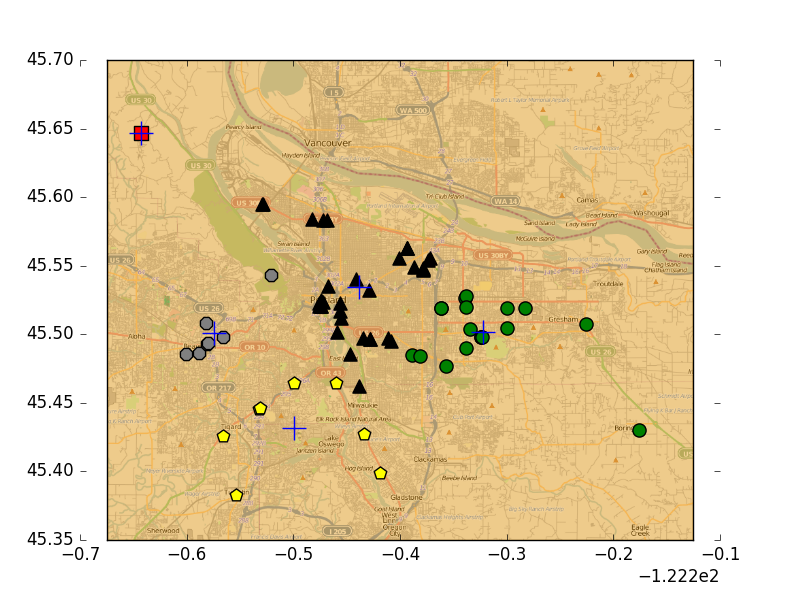
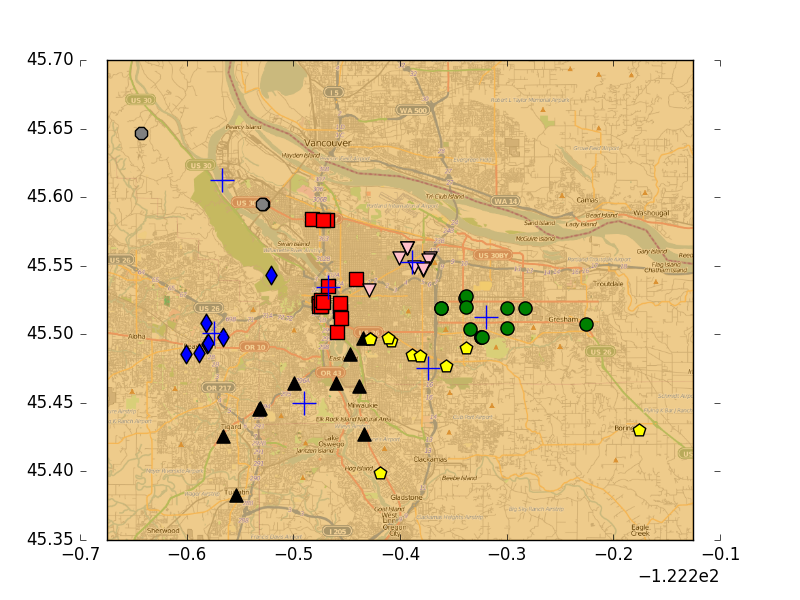
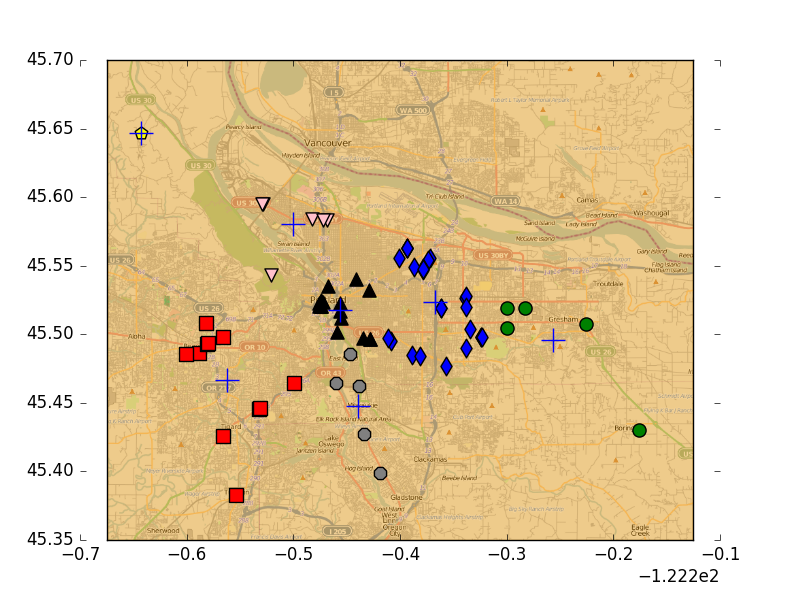
K-均值聚类算法总结
无监督学习指事先不知道要寻找的内容,没有目标变量。聚类将数据点归到多个簇中,可以使用多种方法计算相似度,实际使用时也应多次运行取较优结果。K-均值算法是一种广泛使用的聚类算法,k是用户指定的要创建的簇的数目,该算法非常有效但容易受到初始簇质心的影响。可以使用二分K-均值聚类算法获得更好的效果。
参考文献: 《机器学习实战 - 美Peter Harrington》
原创作品,允许转载,转载时无需告知,但请务必以超链接形式标明文章原始出处(https://forec.github.io/2016/02/21/machinelearning10/) 、作者信息(Forec)和本声明。