图的搜索算法、拓扑排序和边的分类。
摘要
图的搜索算法
图的搜索(此处以遍历为例)指从图中任一顶点出发,对图中所有所有顶点访问一次且只访问一次,是图的基本操作。
广度优先搜索(BFS)
广度优先搜索(BFS)是最简单的图搜索算法之一,在Prim最小生成树和Dijkstra单源最短路径中都采用了广度优先的思想。
- 在给定图G=(V,E)的情况下和某个特定的源点s时,BFS首先从s出发,寻找到图中所有s可到达的顶点(可以同时计算s到这些顶点之间的距离,生成一颗根为s,包括所有s可达顶点的广度优先树)。BFS的特点是沿着已发现顶点和未发现顶点之间的边界向外拓展,也就是说,BFS最先搜索到与s距离为k的所有顶点,在这步操作完成之后,再以这些距离s为k的顶点为基础向外拓展,寻找与s距离为k+1的其他顶点。为了区分已寻找到的顶点和未寻找到的顶点,需要对顶点着色,通常设置一个vis/used数组,boolean类型记录是否访问过。开始时全部为false(白色),在BFS的过程中逐渐染色为true(非白色)。有时为了区分顶点u的相邻顶点是否全部发现,可以对u着灰色或黑色予以区分:灰色表示顶点u可能与一些白色顶点相邻,黑色表示u的相邻顶点全部都是黑色。
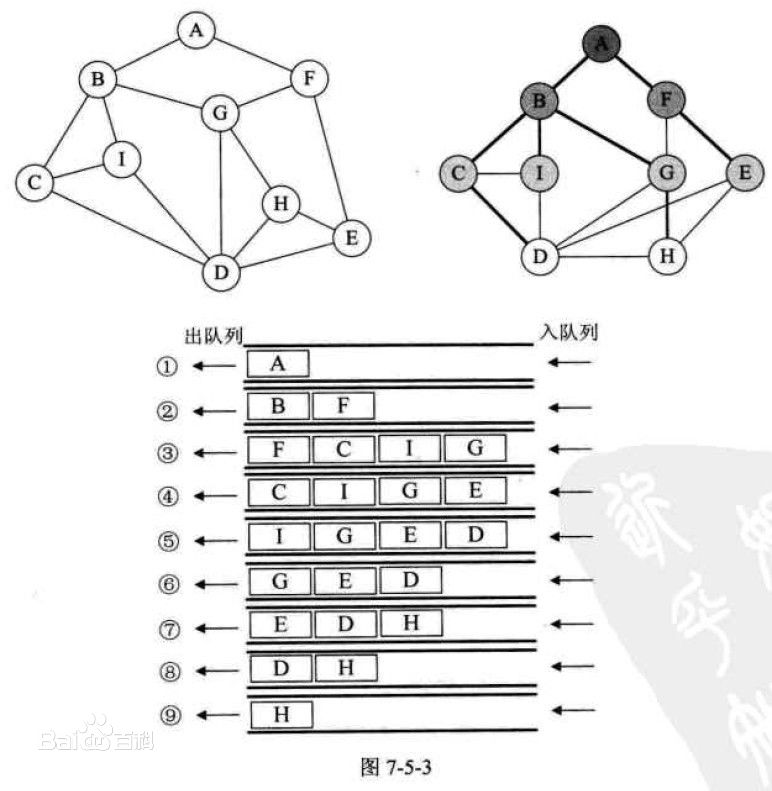
- 整个BFS使用一个队列,开始时将源点s入队,标记s为已访问(used[s] = true),之后每次队首元素u出队,并遍历与u直接相连的顶点v,判断used[v],如果没有访问则标记v为已访问,并将v入队,整个过程直至队列为空结束。下面这张图展示了BFS过程中队列变化的情况,图片来源于网络。
- 代码实现(以有向图邻接表为例,最后输入的是搜索开始的源点)
1 | #include <stdio.h> |
- 上面程序的运行结果依赖于输入的源点。
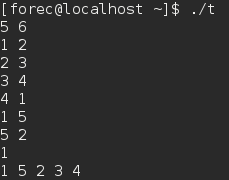
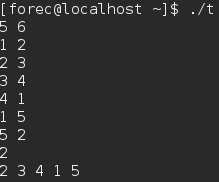
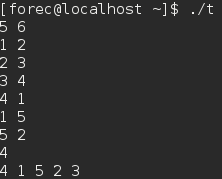
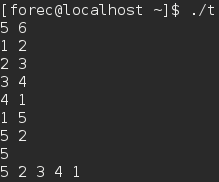
在大多数情况下,广度优先搜索从某个源顶点开始,而不会从多个源顶点开始搜索,例如寻找最短路径距离。而深度优先搜索则多从多个源顶点开始搜索,作为另一个算法的一个子程序。
深度优先搜索(DFS)
与广度优先搜索不同的是,DFS的先辈子图可以由几棵树组成,因为搜索有可能从多个源点开始重复进行。深度优先搜索的先辈子图形成了一个由数棵深度优先树组成的深度优先森林。
- 在搜索过程中,通过对顶点的着色表示顶点的状态。开始时每个顶点都为白色,搜索中发现后即置为黑色(或发现时置为灰色,结束时置为黑色),保证深度优先树互不相交。
- 对于最新发现的顶点,如果它还有以自身为起点并且没有检测过的边,就沿此边继续探测。当某个顶点v的所有边都已经被探寻过,搜索会回溯到v顶点以上的某些仍有未探测边的顶点,直到从源顶点可到达的所有顶点都被探测过,此时查看染色数组,如果仍存在未访问顶点,则选择未访问顶点中的一个作为源点,重复以上过程,直到所有顶点被发现。
- 除了创建深度优先森林外,深度优先搜索同时为每个顶点加盖时间戳(许多图的算法中都用到了时间戳,有助于推算深度优先搜索的进行情况。例如后面的Tarjan)。每个顶点v都有两个时间戳:当v被第一次发现时,记录第一个时间戳d[v],当对v所有可到达顶点检查结束时,为v盖第二个时间戳f[v]。
整个DFS执行过程:初始化将所有顶点染白,pre[]域置空,之后依次检索V中的顶点,发现白色顶点u即调用
DFS_Visit(u)开始访问,每次通过DFS_Visit(u)调用时,顶点u就成为了深度优先森林中一棵新树的根。DFS的结果可能会依赖于顶点访问的顺序(下面代码中有相应解释)。下图是DFS整个过程的示意图,图片来自算法导论。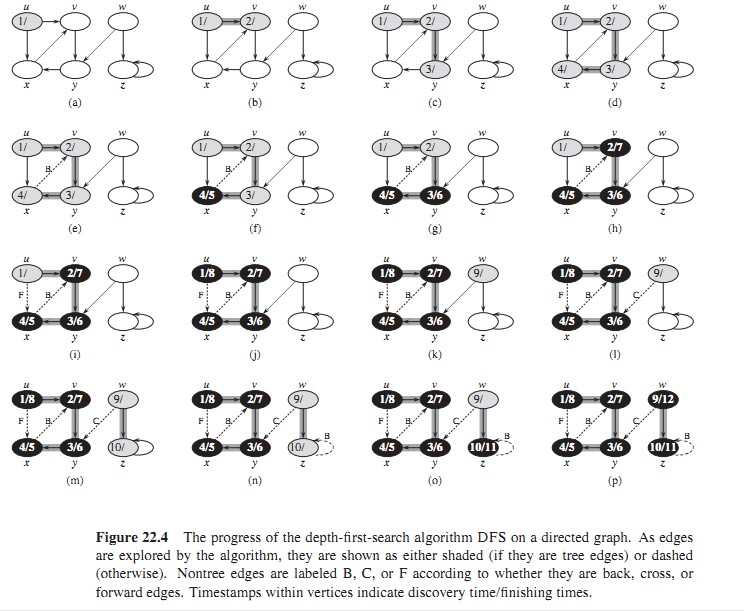
代码实现(有向图邻接表,采取三染色)
1 | #include <stdio.h> |
- 下面两张图分别是代码中注释掉的for循环(从1到V)和未注释的for循环(从V到1)的执行结果。
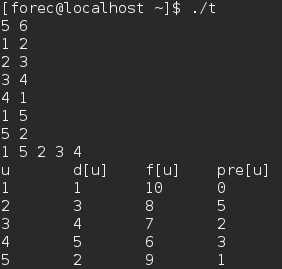
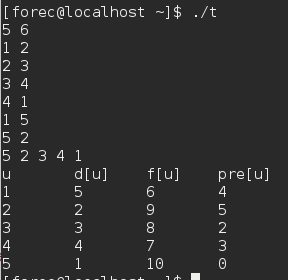
可以看出,最终搜索的顺序依赖于两个for循环的顺序,当然也依赖于DFS_Visit(u)中对u相邻顶点的访问次序。实践中,这些不同的顺序往往不会引起问题,因为任何DFS的搜索结果都可以被有效利用,最终结果基本上等价。 - 给出一些深度优先搜索的性质
- 括号定理:在对一个图(有向或无向)G =(V,E)的任何DFS中,对于图中任意两个顶点u和v,以下三条仅有一条成立:1.区间[d[u], f[u]]和区间[d[v], f[v]]是完全不相交的,并且在深度优先森林中,u或v都不是对方的后裔。2.区间[d[u], f[u]]完全包含于区间[d[v], f[v]]中,且在深度优先树当中,u是v的后裔。3.区间[d[v], f[v]]完全包含于区间[d[u], f[u]]中,且在深度优先树当中,v是u的后裔。
- 后裔区间嵌套:在一个图(有向或无向)G的深度优先森林中,顶点v是顶点u的后裔,当且仅当d[u] < d[v] < f[v] < f[u]。
- 白色路径定理:在一个图(有向或无向)G的深度优先森林中,顶点v是顶点u的后裔,当且仅当在搜索过程中处于时刻d[u]发现u时,可以从顶点u出发,经过一条完全由白色顶点组成的路径到达v。
上面定理的证明都很简单。可以作为判定的技巧使用。
拓扑排序
对一个有向无回路图(dag)G=(V,E)进行拓扑排序后,结果为该图所有顶点的一个线性序列,这个序列满足:如果G包含边(u,v),则在这个序列中,u出现在v的前面(如果图G是有回路的,就不可能有这样的序列)。在很多应用中,有向无回路图用于说明事件发生的先后顺序,如早上起床穿衣的过程:必须先穿好袜子才能穿鞋,其他的一些衣服则可以按任意顺序穿戴(上衣和裤子)。
基于DFS
- 基于DFS:我们在DFS中为每个顶点加盖了时间戳,其中一个f[u]代表着将所有u的可到达顶点扫描完成时的时间。以穿戴为例,可以构造一个有向图,(袜子,鞋)为一条有向边,代表着二者之间的先后顺序:先穿完袜子才可以穿鞋,所以鞋必须在袜子遍历完成之后才能结束遍历,也就是f[鞋] > f[袜子]。因此将DFS完成后的各个顶点按照f[]升序排序,得到的序列即为拓扑序列。当然,拓扑序列显然不是唯一的,可以先穿上衣再穿裤子也可以先穿裤子再穿上衣,这取决于DFS对顶点访问的顺序。
- 代码实现
1 | void DFS_Visit( node ** graph, int u ){ |
只要在DFS_Visit()函数中最后将u添加到拓扑序列L中就可以。
Kahn
- Kahn算法:首先设置拓扑序列为列表L,初始化为空,统计图中每个顶点的入度,将所有入度为0的点组成一个集合S,当S不为空,就从S中取出一个点u,将其加入L的表尾,并将所有与u直接相连的有向边(u,v)删去,并将每个v的入度减一,如果某个v因此入度变为了0,则将v加入S。如此循环往复,直到S为空。此时如果图中仍有边没被删去,则说明图中至少含有一个回路,否则L就是生成的一个拓扑序列。
- 代码实现(有向图邻接表)
1 | #include <list> |
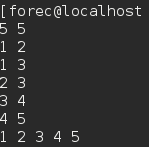
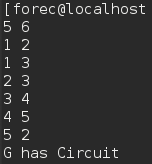
- 以下是运行情况
边的分类
深度优先搜索可以对输入图G =(V,E)的边归类,这种归类可以用来收集很多关于图的重要信息,例如之后会看到这种归类在有向图回路问题中的运用。
- 归类方法
- 树边:是深度优先森林中的边,如果顶点v是在探寻边(u,v)时被首次发现的,则(u,v)为一条树边。
- 反向边:在深度优先树中连接顶点v到达它的某一个祖先顶点u的那些边。有向图中可能出现的自环也被认为是反向边。
- 正向边:在深度优先树中连接顶点u到它的某一个后裔v的非树边(u,v)。
- 交叉边:其它类型的边,存在于同一棵深度优先树的两个顶点之间,条件是其中的一个顶点不是另一个顶点的祖先。交叉边也可以在不同的深度优先树的顶点之间。
修改DFS使其可以对边进行分类
在上面DFS代码中,可以通过三染色对边进行归类。核心在于,对于每条边(u,v),当该边第一次被探寻到时,即根据v的颜色来对该边进行分类(对正向边和交叉边不做区分)。
- 白色:表明(u,v)是一条树边。
- 灰色:表明(u,v)是一条反向边。
- 黑色:表明(u,v)是一条正向边或者交叉边。
- 证明:对第一种情况,白色从定义可知;对第二种情况,灰色顶点对应着DFS_Visit()的调用栈,每次探寻都从最深的灰色顶点开始,所以一旦目标顶点v是灰色,说明v是u的祖先;第三种情况处理其他可能性,并且显而易见:如果d[u] < d[v],则(u,v)是一条正向边,如果d[u] > d[v],则(u,v)是一条交叉边。当然,在无向图中,因为(u,v)和(v,u)是一条边,因此这种分类仅适用前两种(白色,灰色)类型,可以证明:对无向图G深度优先搜索,G的每一条边要么是树边,要么是反向边。
原创作品,允许转载,转载时无需告知,但请务必以超链接形式标明文章原始出处(https://forec.github.io/2015/09/13/Graph-Algorithms2/) 、作者信息(Forec)和本声明。