Unicode和ANSI编码的区别,URL中编码问题,C/C++/Java/Python对两种编码格式的转换
Unicode和ANSI
百科
Unicode (from Wiki)(中文:万国码、国际码、统一码、单一码)对世界上大部分的文字系统进行了整理、编码,使得电脑可以用更为简单的方式来呈现和处理文字。Unicode至今仍在不断增修,每个新版本都加入更多新的字符。目前最新的版本为2015年6月17日公布的8.0.0,已收入超过十万个字符。Unicode发展由非营利机构统一码联盟负责。
ANSI (from Baidu)为使计算机支持更多语言,通常使用 0x80~0xFF 范围的 2 个字节来表示 1 个字符。不同的国家和地区制定了不同的标准,由此产生了 GB2312、GBK、GB18030、Big5、Shift_JIS 等各自的编码标准。不同 ANSI 编码之间互不兼容,当信息在国际间交流时,无法将属于两种语言的文字,存储在同一段 ANSI 编码的文本中。ANSI 编码表示英文字符时用一个字节,表示中文用两个或四个字节。
编码:按照某种规则将文本转换为字节流
解码:将字节流按照某种规则转换为文本
表示
Unicode实现方式
- Unicode只是符号集,规定了符号的二进制代码,没有规定该二进制代码的存储方式。
- UTF-8
- UTF-16
- UTF-32
- 非unicode字元集的UTF-7(提供了一种将Unicode转换为7位US-ASCII的方法:“direct characters”包含了 62 个数字与英文字母,以及包含了九个符号字元:’ ( ) , - . / : ?。这些“direct characters”被认为可以很安全的直接在文件里呈现。“optional direct characters”包含了所有可被列印的字元,这些字元在 U+0020 ~ U+007E 之间,除了~ \ +和空白字元以外。空白字元、Tab字元、以及换行字元一般虽也可直接是为单一的 ASCII 字元来使用,然而,若是邮件中有使用了编码过的字串,则必须特别注意这些字元有无被使用在其他地方。其他的字元则必须被编码成 UTF-16 然后转换为修改的 Base64。这些区块的开头会以 + 符号来标示,结尾则以任何不在 Base64 里定义的字元来标示)。
UTF-8,UTF-16和UTF-32
- UTF-8用1到6个字节编码UNICODE字符,现在已经标准化为RFC 3629。Unicode编码(0x)UTF-8 字节流(01)00000000 - 0000007F0xxxxxxx00000080 - 000007FF110xxxxx 10xxxxxx00000800 - 0000FFFF1110xxxx 10xxxxxx 10xxxxxx00010000 - 001FFFFF11110xxx 10xxxxxx 10xxxxxx 10xxxxxx
00200000 - 03FFFFFF 111110xx 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx 04000000 - 7FFFFFFF 1111110x 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx
(总结自)UTF-8根据字节中开头的bit标志来识别是该多少个字节做为一个单元来处理。
0xxxxxxx ,xx代表任意bit.就表示把一个字节作为一个单元,和ASCII一样.
110xxxxx 10xxxxxx ,把两个字节作为一个单元。
1110xxxx 10xxxxxx 10xxxxxx ,三个字节作为一个单元。在文件的开头几个字节为编码标识,EF BB BF 表示UTF-8,FE FF 表示UTF-16。UTF-8需要判断每个字节中的开头标志信息,当某个字节在传送过程中出错,会导致后面的字节也会解析出错。而UTF-16不会判断开头标志,即使错也只会错一个字符,所以容错能力强。
1997年Unicode2.0加入UTF-32
- UTF-32将所有的字符都用4个字节表示。UTF-8可以选择1至8个字节中的任一个来表示。UTF-16只能为两字节或四字节。
文本开头判断标志(16进制编辑)
EF BB BF UTF-8
FE FF UTF-16LE/UCS-2, little endian
FF FE UTF-16BE/UCS-2, big endian
FF FE 00 00 UTF-32LE/UCS-4, little endian
00 00 FE FF UTF-32BE/UCS-4, big-endian其中的UCS是ISO制定的标准,与Unicode完全相同。UCS-2对应UTF-16,UCS-4对应UTF-32。UTF-8无对应的UCS。
URL中的编码问题
RFC 1738
Only alphanumerics [0-9a-zA-Z], the special characters “$-_.+!*’(),” [not including the quotes - ed], and reserved characters used for their reserved purposes may be used unencoded within a URL.
不同情况下的编码
网址路径中存在非法字符
随机输入一个包含中文的网址
打开开发者工具可以看到http请求的头信息
测试的浏览器是firefox40.0,可以看到编码为UTF-8(图中E4 B8 AD E5 9C 8B为‘中国’的UTF-8编码)

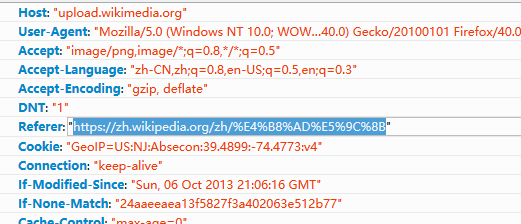
发送的查询字符串中存在非法字符
在谷歌中搜索“火狐”,根据测试浏览器给出的编码方式仍然为UTF-8。
但是根据查找的资料(引用),这种情况下会使用操作系统的默认编码。测试系统为windows10,使用的默认编码不是GB2312而是UTF-8。在XP虚拟机中默认编码为GB2312,此时浏览器使用的编码方式为GB2312。
GET方法生成的URL存在非法字符
直接搬过来,没有测试

代码实现转换
C语言/C++
- ANSI:char,可用函数:strcat(),strcpy(),strlen()等,以str开头。
UNICODE:wchar_t,可用函数:wcscat(),wcscpy(),wcslen()等,以wcs开头。
详细介绍及系统支持 - 代码(需要win32API,原创在gakusei)
Unicode -> ANSI
1 | string UnicodeToANSI( const wstring& str ){ |
ANSI -> Unicode
1 | wstring ANSIToUnicode( const string& str ){ |
UTF-8 -> Unicode
1 |
|
Unicode -> UTF-8
1 | string UnicodeToUTF8( const wstring& str ){ |
Java
- 将字符串按不同编码方式读取
1 | String text = “TESTSTRING”; |
- 将ansi文件转为UTF-8
1 | private static void transferFile(String srcFileName, String destFileName) throws IOException { |
Python
获取系统默认编码
1 | #coding=utf-8 |
编码间转换
通常通过Unicode作为中间编码
1 | str.decode('gb2312'); //将GB2312的字符串str转换为unicode编码 |
1 | import sys |
原创作品,允许转载,转载时无需告知,但请务必以超链接形式标明文章原始出处(https://forec.github.io/2015/08/14/ANSI-Unicode备忘/) 、作者信息(Forec)和本声明。