整理《Operating System Concepts》 第七版第三、四章的理论和概念,内容均为原书和中文版翻译的摘录,其中原书摘录部分由我 按个人理解简化、翻译为中文,可能存在一些不准确之处 。
进程(第三章)
概念与调度
- 进程可看作正在执行的程序,是大多数系统中的工作单元。进程除了包括程序代码(有时也称作 文本段 ),还包括用 程序计数器 和处理器寄存器来表示的当前活动。进程通常还包括进程 堆栈段(stack) 和 数据段(data section) ,其中堆栈段保存临时数据如函数参数、返回地址、局部变量,数据段保存全局变量。进程还可能包括 堆(heap) ,堆是进程运行期间动态分配的内存。
- 进程在执行中会改变 状态(state) ,每个进程可能处于下列状态:
- 创建(New) :进程正在被创建
- 运行(Running) :进程正在被执行
- 等待(Waiting) :进程在等待某个事件发生(如 I/O 完成或接收到某个信号)
- 就绪(Ready) :进程等待分配处理器
- 终止(Terminated) :进程完成执行
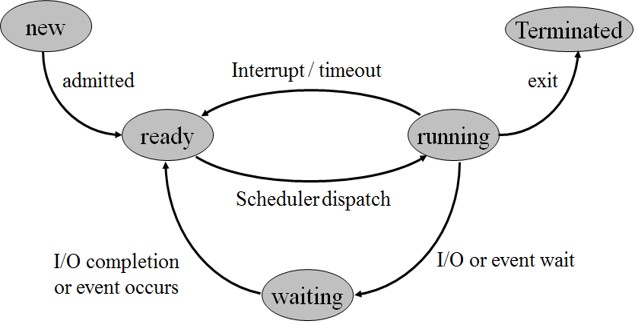
- 一次只有 一个进程 可以在 一个处理器 上 运行 ,但可以有多个进程处于 就绪 或 等待 状态。进程状态转移如下图,图片根据原书内容制作。
- 每个进程在操作系统内部用 进程控制块(process control block,PCB) 来表示,它包含了与一个特定进程相关的信息。每个进程控制块包含:
- 进程状态(process state) :可为上述五种状态
- 程序计数器(program counter) :指定进程要执行的下条指令地址
- CPU 寄存器 :根据计算机体系结构的不同,寄存器数量、类型也不同,多数包括累加器、索引寄存器、堆栈指针、通用寄存器等
- CPU 调度信息(CPU-scheduling information) :包括进程优先级、调度队列的指针和其它调度参数
- 内存管理信息(memory-management information) :根据内存系统,通常包括基址、界限寄存器值、页表或段表
- 统计信息(accounting information) :包括 CPU 时间、实际使用时间、时间界限、统计数据、作业/进程数量等
- I/O 状态信息 :包括分配给进程的 I/O 设备列表、打开的文件列表等
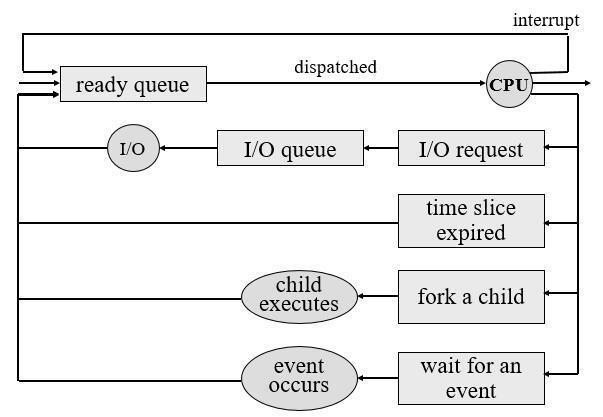
- 进程调度器(process scheduler) 选择一个可用的进程到 CPU 中执行。进程进入系统时会被加入到 作业队列(job queue) 中,该队列包括系统中所有进程。保留在主存中且准备就绪等待运行的进程被保存在 就绪队列(ready queue) 中,该队列通常用链表实现,头节点指向了链表的第一个和最后一个 PCB 块指针,每个PCB 包括指向就绪队列的下一个 PCB 的指针。有些进程向共享设备(如磁盘)发送 I/O 请求,若磁盘正忙则该进程需要等待。等待特定 I/O 设备的进程列表称为 设备队列(device queue) ,每个设备都有自己的设备队列。
- 新进程开始时处于就绪队列,它在就绪队列中等待直到被选中执行或 派遣(dispatched) 。一旦进程被分配 CPU 并开始执行,可能发生以下事件。在前两种情况中,经过一定时间的等待,进程最终会从等待状态切换回就绪状态,并放回到就绪队列中。
- 进程发出一个 I/O 请求并被放到 I/O 队列中
- 进程创建一个新的子进程并等待其结束
- 进程由于中断强制释放 CPU,并被放回到就绪队列中
- 操作系统从队列中选择进程的操作由 调度程序(scheduler) 执行。在批处理系统中,进程被放到大容量存储设备(如磁盘)的缓冲池(作业池)中等待执行。 长期调度程序(long-term scheduler) 或 作业调度程序(job scheduler) 从缓冲池选择进程、装入内存以准备执行,而 短期调度程序(short-term scheduler) 或 CPU 调度程序 从准备执行的进程中选择并分配 CPU。二者的区别主要体现在 执行的频率不同 。短期调度程序非常频繁地执行,为CPU选择新进程,如果短期调度需要 10ms 来确定执行一个运行 100ms 的进程,则
10/(100+10) = 9% 的CPU时间浪费在了调度工作上;而长期调度程序执行不频繁,可能数分钟调度一次,它控制 多道程序设计的程度(degree of multiprogramming) ,即内存中的进程数量。只有进程离开系统后才可能需要调度长期调度程序。
- 有些系统没有/少有长期调度程序,如 UNIX 或 Windows 的分时系统通常没有长期调度程序,它们仅仅简单的将所有新进程放到内存中以供短期调度程序使用。有些系统如分时系统可能引入 中期调度系统(medium-term scheduler) ,它可以将进程从内存(或 CPU 竞争)中移出,从而降低多道程序设计的程度。之后,这些进程可以被重新调入内存并从中断处继续执行。这种行为称为 交换(swapping) 。有时因为内存要求的改变导致可用内存过度使用,此时便需要交换。
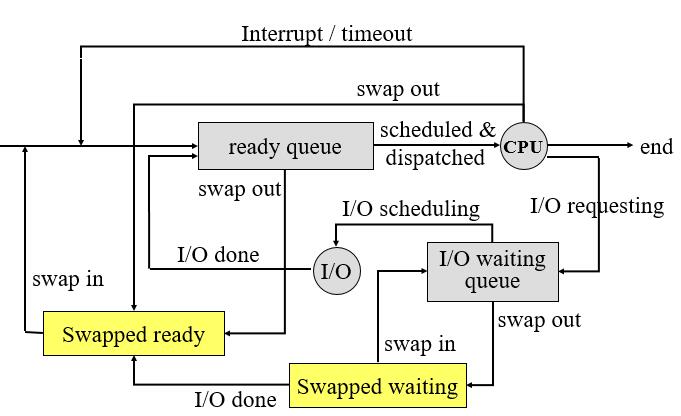
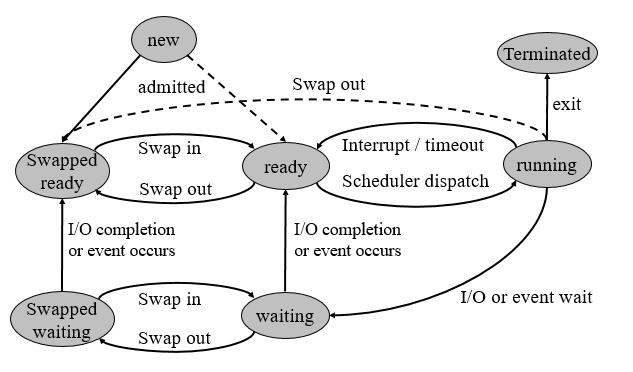
- 将 CPU 切换到另一个进程需要保存当前进程状态并恢复另一个进程的状态,此任务称为 上下文切换(context switch) 。内核会将旧进程的状态保存在其 PCB 中,并装入调度后要执行的并已恢复的新进程的上下文。上下文切换的时间与硬件支持相关。
进程操作
- 进程在其执行过程中能通过创建进程系统调用(create-process system call)创建多个新进程。创建进程称为 父(parent)进程 ,被创建的新进程称为 子(children)进程 。每个新进程可以再创建其他进程以形成 进程树(tree) 。
- 多数操作系统根据一个唯一的 进程标识符(process identifier,pid) 来识别进程,通常是整数值。
- 一个进程创建子进程时,子进程可能通过以下方式获取资源:
- 从操作系统直接获取资源
- 获取父进程资源。父进程需要在子进程之间分配或共享资源,父进程可以选择和子进程分享全部资源、分享部分资源、不分享资源
- 进程创建时,除了得到各种物理和逻辑资源,初始化数据(或输入)由父进程传递给子进程。
- 当进程创建新进程时,存在两种执行可能:
- 父进程和子进程并发执行
- 父进程等待,直到某个或全部子进程执行完
- 新进程的地址空间有两种可能:
- 子进程是父进程的副本,具有和父进程相同的程序和数据
- 子进程装入另一个新程序
- 在 UNIX 中,通过
fork() 系统调用创建新进程,新进程通过 复制原来进程的地址空间形成 。两个进程(父进程、子进程)均继续执行位于系统调用 fork() 之后的指令,对于子进程,系统调用 fork() 返回值为 0,而父进程的返回值为子进程的 pid。
- 在系统调用
fork() 后,一个进程会使用系统调用 exec() 以使用新程序取代进程内存空间并开始执行。这样两个进程可以相互通信且执行各自程序。如果父进程在子进程运行时需要等待,则采用系统调用 wait() 将自己移出就绪队列来等待子进程终止。
- 以下是 UNIX 系统一个 C 语言例程,来自原书第 92 页。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| #include <sys/types.h>
#include <stdio.h>
#include <unistd.h>
int main(){
pid_t pid;
pid = fork();
if (pid < 0){
exit(-1);
} else if (pid == 0){
execlp("/bin/ls", "ls", NULL);
} else {
wait(NULL);
exit(0);
}
}
|
- 以下是 Win32 API 生成一个单独进程的 C 语言例程,来自原书第 94 页。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
| #include <stdio.h>
#include <windows.h>
int main(){
STARTUPINFO si;
PROCESS_INFORMATION pi;
ZeroMemory(&si, sizeof(si));
si.cb = sizeof(si);
ZeroMemory(&pi, sizeof(pi));
if (!CreateProcess(NULL,
"C:\\WINDOWS\\system32\\mspaint.exe",
NULL, NULL, FALSE, 0, NULL, NULL, &si, &pi)){
return -1;
}
WaitForSingleObject(pi.hProcess, INFINITE);
CloseHandle(pi.hProcess);
CloseHandle(pi.hThread);
}
|
进程终止和通信
- 进程完成执行最后的语句并使用系统调用
exit() 时进程终止,此时进程可以返回状态值(通常为整数)给父进程(通过wait()获取),所有进程资源也会被操作系统释放。
- 进程通过系统调用(如 Win32 的
TerminateProcess())可以终止另一个进程,通常只有被终止进程的父进程才能执行该操作。父进程终止子进程的原因如:
- 子进程使用了超出其所分配的资源
- 子进程所分配的任务已不需要
- 父进程退出(在有的系统中,如果父进程终止,则其所有子进程也终止,此现象称为 级联终止(cascading termination) 。而在 UNIX 中,若父进程终止,其所有子进程会以 init 进程作为父进程,因此子进程仍然有一个父进程来收集状态和执行统计。)
- 操作系统内并发执行的进程可以为 独立进程 或 协作进程 。如果一个进程不能影响其他进程,也不能被其他进程所影响,则该进程是 独立(independent) 的,否则该进程是 协作(cooperating) 的。进程协作的原因有很多,如:
- 信息共享(information sharing) :多个用户需要同一个共享文件
- 提高运算速度(computation speedup) :要使一个特定任务快速运行,则需要将其分成子任务以并行执行,这需要计算机有多个处理单元(CPU或 I/O通道)
- 模块化(modularity) :需要按模块化方式构造系统
- 方便 :单个用户可同时执行多个任务
- 进程协作需要 进程间通信机制(interprocess communication, IPC) 来允许进程相互交换数据,其包括两种基本模式:
- 共享内存(shared memory) :通信进程需要建立内存共享区域
- 消息传递(massage passing) :在分布式环境中非常有用,通信进程之间必须有 通信线路(communication link) 。对于 直接通信 ,采用对称寻址,每个进程必须明确地命名通信的接收者或发送者; 间接通信 中,通过 邮箱(mailboxes) 或 端口(ports) 来发送和接收消息,每个邮箱都有唯一的标识符,两个进程仅在其共享至少一个邮箱时可相互通信,一个进程可通过许多不同的邮箱和其他进程通信。
- 对于使用邮箱的间接通信,通信线路有如下属性:
- 只有在两个进程共享一个邮箱时才能建立通信线路
- 一个线路可以与两个或更多的进程相关联
- 两个通信进程之间可有多个不同线路,每个线路对应一个邮箱
- 若多个进程共享同一个邮箱,例如进程 P1、P2、P3均共享邮箱 A,进程 P1 发送一个消息到 A,进程 P2 和 P3 同时对邮箱 A 执行
receive(),则结果取决于所选用的方案:
- 允许一个线路最多只能与两个进程相关联
- 一次最多允许一个进程执行
receive() 操作
- 允许系统随意选择一个进程接收消息
- 由操作系统所拥有的邮箱是独立存在的,不属于某个特定的进程。创建新邮箱的进程默认为邮箱拥有者,通过系统调用,拥有和接收的特权可能传递给其他进程。
- 消息传递可以是 阻塞(blocking) 或者 非阻塞(nonblocking) ,也称为 同步(synchronous) 或 异步(asynchronous) 。
- 阻塞发送:发送进程阻塞直到消息被接收进程或邮箱接收
- 非阻塞发送:发送进程可直接发送消息并继续操作
- 阻塞接收:接收者阻塞直到有可用消息
- 非阻塞接收:接收者可以直接收到一个有效消息或空消息
- IPC 系统示例,Windows XP:Windows XP 的消息传递工具称为 本地过程调用(local procedure call,LPC) 工具,在位于同一机器的两个进程之间通信。Windows XP 使用了端口对象以建立、维持两个进程之间的链接。通信工作如下,如果客户端要发送更大的消息,则可通过 区段对象(section object) 来构建共享内存传递消息。注意,LPC 不是 Win32 API 的一部分,所以对应用程序不可见。
- 客户端打开系统的连接端口对象句柄
- 客户端发送连接请求
- 服务器创建两个私有通信端口,并返回其中之一的句柄给客户端
- 客户端和服务器使用相应端口句柄以发送消息或回调,并等待回答
- 例程,C 程序调用 POSIX 系统下的共享内存 API,来自原书(英文版)第 104 页。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
| #include <stdio.h>
#include <sys/shm.h>
#include <sys/stat.h>
int main(){
int segment_id;
char *shared_memory;
const int size = 4096;
segment_id = shmget(IPC_PRIVATE, size, S_IRUSR | S_IWUSR);
shared_memory = (char *) shmat(segment_id, NULL, 0);
sprintf(shared_memory, "Hi there!");
printf("*%s\n", shared_memory);
shmdt(shared_memory);
shmctl(segment_id, IPC_RMID, NULL);
return 0;
}
|
管道(补充)
- 管道(pipe) 是一条在进程间以字节流方式传送数据的通信通道,由OS核心的缓冲区(通常几十KB)来实现,为单向。
- 管道常用于命令行所指定的输入输出重定向和管道命令,使用前要建立相应的管道。管道逻辑上可以看作管道文件,物理上则是由文件系统的高速缓存区构成。
- 管道分为 有名管道 和 无名管道 ,按先进先出(FIFO)的方式传送消息,且 只能单向传送消息 。
- 管道的发送和接受可使用如下操作:
- 发送进程利用文件系统的系统调用
write(fd[1], buf, size) 把 buf 中长度为 size 字符的消息送入管道入口 fd[1];
- 接收进程利用文件系统的系统调用
read(fd[0], buf, size)从管道出口 fd[0] 读出 size 字符的消息放入 buf 中。
- 管道应用例程,来自李文生老师的操作系统幻灯片。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
| #include <stdio.h>
int main(){
int pid,fd[2];
char buf[30], s[30];
pipe(fd);
while((pid = fork()) == -1);
if (pid==0){
sprintf(buf, "this is an example\n");
write(fd[1],buf,30);
exit(0);
} else {
wait(0);
read(fd[0], s, 30);
printf("%s",s);
}
}
|
线程(第四章)
- 线程是 CPU 使用的基本单元,由线程ID、程序计数器、寄存器集合和栈组成。它和 属于同一进程 的其他线程共享代码段、数据段和其他操作系统资源(打开文件、信号等)。传统 重量级(heavyweight) 的进程只有单个控制线程,若进程有多个控制线程,则可同时做多个任务。
- 多线程编程优点:
- 响应度高
- 资源共享:线程默认共享它们所属进程的资源和内存,它允许一个应用程序在同一地址空间有多个不同的活动线程
- 经济:线程创建所需的内存和资源较进程少很多
- 多处理器体系结构的利用:每个进程能并行运行在不同处理器上,加强了并发功能
多线程模型
有两种方法提供线程支持:用户层的 用户线程(user threads) 和内核层的 内核线程(kernel threads) 。用户线程受到内核的 支持 ,但不需内核管理;内核线程 由操作系统直接支持和管理 。当代所有操作系统均支持内核线程。
- 多对一模型(Many-to-One) :将多个用户级线程映射到一个内核线程。 线程管理是由线程库在用户空间进行的 ,效率较高; 若一个线程执行了阻塞系统调用,则整个进程都会阻塞 ,因为任一时刻只有一个线程能访问内核。
- 一对一模型(One-to-One) :将每个用户线程映射到一个内核线程,该模型在一个线程执行系统调用时,能允许另一个线程继续执行,所以它提供了更好的并发性能;缺点在于每个用户线程需要创建一个对应的内核线程,因此限制了系统支持的线程数量。Linux 和 Windows 系列系统实现了一对一模型。
- 多对多模型(Many-to-Many) :复用了许多用户线程到同样数量或者更小数量的内核线程上,开发人员可创建任意多的用户线程,并且相应内核线程能在多处理器系统上并发执行。一个流行的多对多模型的变种允许将一个用户线程绑定到某个内核线程上,这个变种有时称为 二级模型(two0level model) 。
线程库
- 线程库(thread library) 为程序员提供创建和管理线程的 API。有两种方法来实现:
- 在用户空间提供一个没有内核支持的库,此库的所有代码和数据结构均存在用户空间中,调用库中的一个函数只是导致用户空间中一个本地函数的调用,而非系统调用
- 执行一个由操作系统直接支持的内核级的库,库的代码和数据结构存储在内核空间中,调用库中的一个 API 会导致对内核的系统调用。
- 目前主要的三种线程库有:POSIX Pthread、Win32 和 Java。
- Pthread 创建、执行线程的一个 C程序样例如下,例程来自原书(英文版)第 133 页。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
| #include <pthread.h>
#include <stdio.h>
int sum = 0;
void *runner(void *param);
int main(int argc, char *argv[]){
pthread_t tid;
pthread_attr_t attr;
if (argc != 2){
return -1;
}
if (atoi(argv[1]) < 0){
return -1;
}
pthread_attr_init(&attr);
pthread_create(&tid, &attr, runner, argv[1]);
pthread_join(tid, NULL);
printf("sum = %d\n", sum);
}
void *runner(void *param){
int i, upper = atoi(param);
for (i = 1; i <= upper; i++)
sum += i;
pthread_exit(0);
}
|
- Win32 线程库创建线程的例程如下,来自原书(英文版)第 135 页。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
| #include <windows.h>
#include <stdio.h>
DWORD sum = 0;
DWORD WINAPI Summation(LPVOID Param){
DWORD Upper = *(DWORD*)Param;
for (DWORD i = 0; i <= Upper; i++){
Sum += i;
}
return 0;
}
int main(int argc, char *argv[]){
DWORD ThreadId;
HANDLE ThreadHandle;
int Param;
if (argc != 2){
return -1;
}
if ((Param = atoi(argv[1])) < 0){
return -1;
}
ThreadHandle = CreateHandle(
NULL,
0,
Summation,
&Param,
0,
&ThreadId);
if (ThreadHandle != NULL){
WaitForSingleObject(ThreadHandle, INFINITE);
CloseHandle(ThreadHandle);
printf("sum = %d\n", Sum);
}
}
|
多线程问题
- 在多线程程序中,
fork() 和 exec() 的语义有所改变:有的 UNIX 系统存在两种形式的 fork(),如果程序中一个线程调用 fork(),其中一种情况新进程会复制所有线程,另一种则只复制调用系统调用 fork() 的线程。
exec() 工作方式不变, 如果一个线程调用了系统调用 exec(),则exec()参数指定的程序会替换整个进程,包括所有线程 。fork() 的两种工作方式和应用程序有关:如果调用 fork() 后立刻调用 exec(),则没必要复制所有线程,因为 exec() 会替换整个进程,此时应当只复制调用的线程,否则应当复制所有线程。- 线程取消(thread cancellation) 指线程完成之前终止线程任务,要取消的线程通常称为 目标线程(target thread) ,目标线程的取消可在如下两种情况下发生:
- 异步取消(asynchronous cancellation) :一个线程立刻终止目标线程
- 延迟取消(deferred cancellation) :目标线程不断检查它是否应当终止
- 如果资源已分配给要取消的线程或要取消的线程正在更新与其他线程所共享的数据,则取消会非常麻烦。采用延迟取消时,只有当目标线程检查它在安全的点时才会取消,Pthread 称这些点为 取消点(cancellation point) 。
- 信号处理: 信号(signal) 在 UNIX中用来通知进程某个特定事件发生,根据需要通知信号的来源和事件理由,无论信号为异步还是同步,它们都具有同样的模式:
- 信号由特定事件产生
- 产生信号要发送给进程
- 信号一旦被发送就必须被处理
- 同步信号的例子包括访问违例内存或者除 0,同步信号发送到执行操作而产生信号的同一进程;如果一个信号由运行进程之外的事件产生,则进程异步接收这一信号,如使用Ctrl + C 终止或定时器到期。异步信号通常被发送到另一个进程。每个信号可能由两种可能的处理程序中的一种来处理:
- 对于多线程程序,一个信号的接收者可以是以下四种:
- 信号适用(能够处理这个信号)的线程;
- 进程内的每个线程
- 进程内的部分固定线程
- 进程规定一个特定的线程来接收全部的信号
- Windows 并不提供对信号的支持,但它们能通过 异步过程调用(asynchronous procedure call,APC) 来模拟。APC 工具允许用户线程指定一个函数以便在用户线程受到特定事件通知时能被调用。
线程池和特定数据
- 如果允许所有并发请求都通过新线程来处理,则没法限制在系统中并发执行的线程的数量。可使用 线程池(thread pool) 解决:在进程开始时创建一定数量的线程,并放入池中等待工作,当服务器收到请求则唤醒池中一个线程(如果有线程可用),并将要处理的请求传递给该线程;一旦一个线程完成了服务,它会返回池中等待工作。
- 线程池优点主要有:
- 使用现有线程处理请求比等待新创建线程更快
- 线程池限制了在任何时候可以使用的线程数量
- 有些情况下线程自己需要维持一定数据的副本,这类数据称为 线程特定数据(thread-specific data) 。
专栏目录:计算机理论基础
此专栏的上一篇文章:操作系统(一):概念导读
此专栏的下一篇文章:操作系统(三):CPU 调度
参考资料:《操作系统概念 英文第七版》,恐龙书,英文名《Operating System Concepts》,作者 Abraham Silberschatz、Peter Baer Galvin、Greg Gagne
原创作品,允许转载,转载时无需告知,但请务必以超链接形式标明文章原始出处(http://blog.forec.cn/2016/11/22/os-concepts-2/) 、作者信息(Forec)和本声明。