在低维下,数据更容易进行处理,其相关特征可能在数据中明确显示出来。PCA是降维技术中最广泛的一种。
降维技术
- 数据往往拥有超出显示能力的更多特征,简化数据不止使得数据容易显示,同时降低算法计算开销、去除噪声、使得结果易懂。
- 主成分分析(Principal Component Analysis,PCA)将数据从原来的坐标系转移到新的坐标系,新坐标系的选择由数据本身决定,新坐标系的第一个坐标轴是原始数据中方差最大的方向,新坐标系的第二个坐标轴和第一个坐标轴正交、并且具有最大方差。该过程一直重复,次数为原始数据中维度。大部分方差都包含在前面几个新坐标轴中,因此可以忽略剩下的坐标轴。
- 因子分析(Factor Analysis)假设观察数据的生成中有一些观察不到的隐变量,即观察数据是由这些隐变量和某些噪声的线性组合,那么隐变量的数据可能比观察数据的数目少,找到隐变量就可以实现数据的降维。
- 独立成分分析(Independent Component Analysis,ICA)假设数据从N个数据源生成,类似因子分析,假设这些数据源之间在统计上相互独立,如果数据源数目少于观察数据数目,就实现降维过程。
PCA
- PCA可以降低数据复杂性,识别最重要的多个特征,但有时不一定需要,并且可能损失有用信息。适用于数值型数据。
- 对于下图的数据,要找出一条直线尽可能覆盖这些点,第一条坐标轴旋转到最大方差的方向,数据的最大方差给出了数据的最重要的信息。在选择了覆盖数据最大差异性的坐标轴之后,选择第二条坐标轴与第一条正交。
 在下面的示例中,只需要一维信息,另一维信息只是对分类缺乏贡献的噪声数据。可以采用决策树,也可以使用SVM获得更好的分类间隔,但是分类超平面很难解释。PCA降维可以同时获得SVM和决策树的优点。
在下面的示例中,只需要一维信息,另一维信息只是对分类缺乏贡献的噪声数据。可以采用决策树,也可以使用SVM获得更好的分类间隔,但是分类超平面很难解释。PCA降维可以同时获得SVM和决策树的优点。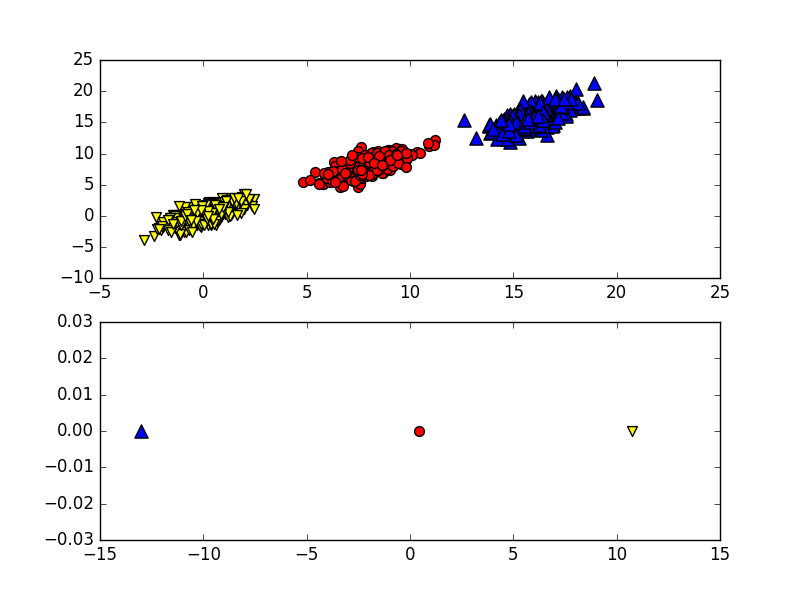
- PCA过程实现:第一个主成分从数据差异性最大的方向获取,可以通过数据集的协方差矩阵 Convariance和特征值分析求得。下面pca函数的流程为,首先去除平均值,之后计算协方差矩阵
cov,计算协方差矩阵的特征值和特征向量linalg.eig,将特征值从大到小排序,保留对应的最上面的N个特征向量,最后将数据转换到上述N个特征向量构建的新空间中。
1 | from numpy import * |
- 运行示例如下,下图是构造出的第一主成分。
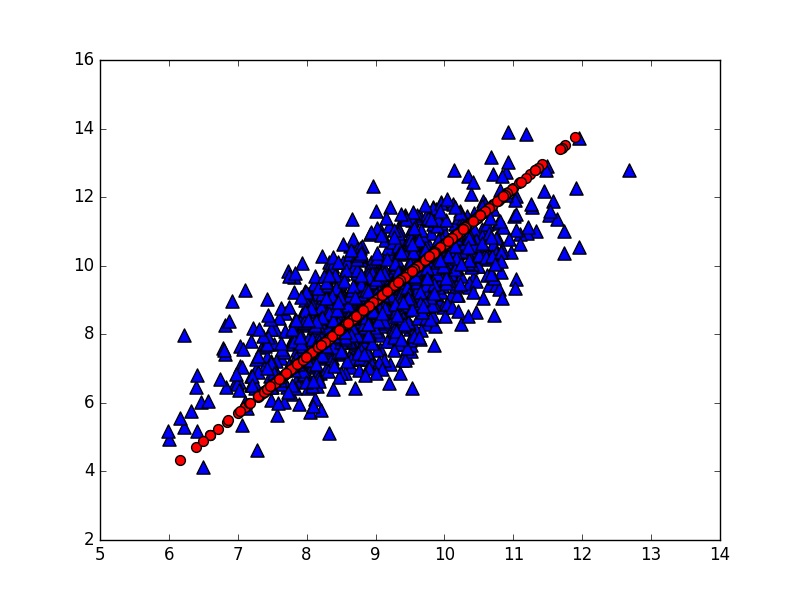
1 | >>> dataMat = pca.loadDataSet('testSet.txt') |
利用PCA对半导体制造数据降维
- 数据集来自UCI机器学习数据库,包含590个特征,其中几乎所有样本都存在特征缺失,用NaN表示,通过replaceNanWithMean将缺失的NaN数据用其他样本的相同特征值平均值填充。
1 | def replaceNanWithMean(): |
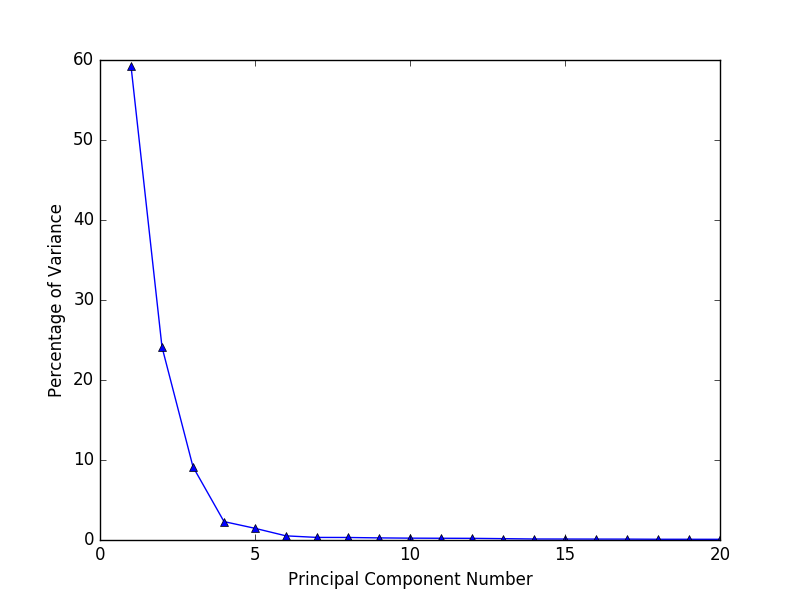
- 从特征值可以看出,有超过20%特征值为0,这些特征都是其他特征的副本。
1 | >>> dataMat = pca.replaceNanWithMean() |
- 下图是前二十个主成分占总方差的百分比,大部分方差都包含在前面几个主成分中,前6个特征覆盖了96.8%的方差。因此可以将590个特征缩减到这6个特征。现实中我们无法精确知道所需要的主成分数目,必须通过实验取不同值来确定。
PCA总结
降维技术使数据更易使用,并且它们往往能够去除数据中的噪声,通常作为预处理步骤,在算法应用前清洗数据。PCA可以从数据中识别主要特征,它通过沿着数据最大方差方向旋转坐标轴实现。如果要处理的数据过多无法放入内存,可以使用在线PCA分析,参考论文“Incremental Eigenanalysis for Classification”。
参考文献: 《机器学习实战 - 美Peter Harrington》
原创作品,允许转载,转载时无需告知,但请务必以超链接形式标明文章原始出处(https://forec.github.io/2016/02/25/machinelearning13/) 、作者信息(Forec)和本声明。